

数据采集是指采用技术手段从大量网页中提取结构化和非结构化信息,按照一定规则和筛选标准进行数据处理,并保存到结构化数据库中的过程。面对海量的互联网数据,数据采集系统软件被视为一种行之有效的技术手段。相比于传统的数据采集方法,网络数据采集软件无论时效性,还是灵活性均有一定的优势。利用数据采集系统软件,可以在短时间内快速地抓取目标信息,构建大数据集以满足分析研究需要。
数据采集软件的核心目的在于获取有价值的信息,为后续的数据处理、分析和决策提供基础。在商业领域,企业通过数据采集系统软件采集消费者的购买行为数据、浏览记录等,可以深入了解消费者的需求和偏好,从而制定更加精准的营销策略。
如您需要爬虫数据采集服务,可与晨域公司联系,电话:13331218608,微信同号。

【数据采集软件系统程序】
Python爬虫:使用Python语言编写数据采集程序,可以通过请求网页、解析HTML代码等方式获取所需数据。Python是一种常用的数据采集方式,具有灵活、高效的特点。
Selenium:它可以模拟浏览器行为,通过控制浏览器实现页面自动化操作和数据采集。Selenium支持多种浏览器,并且具有良好的兼容性和稳定性。
Scrapy:是一个基于Python的开源网络爬虫框架,支持分布式爬取、异步处理等功能。使用Scrapy框架可以实现高效、稳定地采集目标网站上的数据。
Apache Nutch:是一个开源的Web搜索引擎,使用Nutch可以实现高效、准确地采集目标网站上的数据,并可通过配置文件进行二次开发。
Charles:是一款常用的HTTP代理工具,可以用于数据采集。它可以截取网络请求和响应数据,并可对数据进行过滤、修改等操作。
Wireshark:是一款开源的网络协议分析器,也可以用于数据采集。它可以截取网络请求和响应数据,并可对数据进行解码、分析等操作。
Fiddler:是一款免费的Web调试工具,也可以用于数据采集。它可以截取网络请求和响应数据,并可对数据进行过滤、修改等操作。
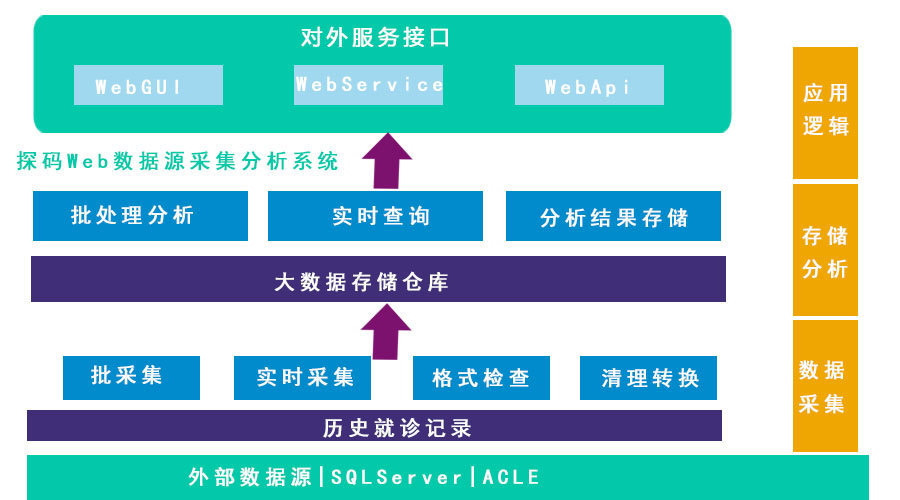
【常见数据采集系统软件】
火车头采集器:火车头采集器是一款老牌的数据采集软件,支持多线程并发采集,能够高效地抓取网页上的信息,特别适用于大量数据的快速抓取。
神箭手云爬虫:神箭手云爬虫是一款基于云计算的数据采集系统工具,用户可以通过简单的拖拽操作来定义抓取规则,无需编写复杂的代码。
Web Scraper:是一款非常简单好用的浏览器扩展插件,专门用于数据采集,在浏览器上直接抓网页。你不需要安装额外的软件,即可在Chrome浏览器中进行爬虫。
Flume:由 Cloudera 公司开发,是一个分布式、高可靠、高可用的海量日志采集、聚合、传输的系统。Flume 支持在日志系统中定制各类数据发送方,用于采集数据;Flume 提供对数据进行简单处理,并写到各种数据接收方的能力。简单的说,Flume 是实时采集日志的数据采集引擎。
Fluentd:是一个开源的数据采集系统软件。Fluentd 使用 C/Ruby 开发,使用 JSON 文件来统一日志数据。通过丰富的插件,可以收集来自各种系统或应用的日志,然后根据用户定义将日志做分类处理。通过 Fluentd,可以非常轻易地实现像追踪日志文件并将其过滤后转存到 MongoDB 这样的操作。Fluentd 可以彻底地把人从烦琐的日志处理中解放出来。
 :1299073570 网店:qushuiyin.taobao.com
:1299073570 网店:qushuiyin.taobao.com 


