

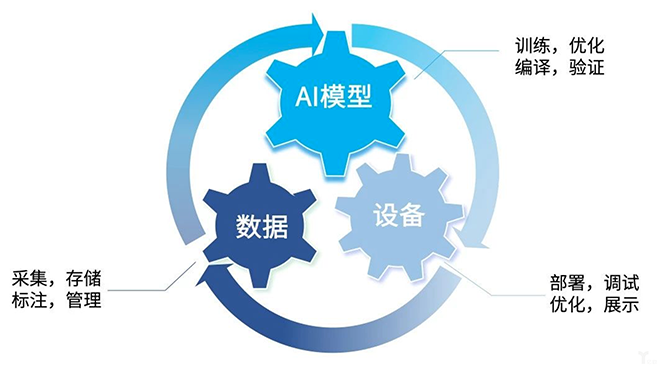
AI语料(Artificial Intelligence Corpus)是指用于训练、优化人工智能系统的结构化数据集合。这些数据可以是文本、语音、图像或视频等形式,通过标注、清洗和分类处理后,为AI大模型训练提供学习素材。
大规模、高质量的语料库是训练和评估AI大模型的基础。从海量语料数据中提取语法结构、语义特征能够提升模型泛化性和准确性。语料训练库成为影响 AI 大模型效果的重要差异化环节,其规模、质量与多样性直接影响AI 大模型的性能和应用效果,高质量语料库可以提高模型性能和训练效率。
晨域软件公司是一家有科研背景、以技术发展为导向的AI大模型基础数据服务企业,为数家人工智能从业公司和高校科研机构提供AI大模型语料采集、数据标注、语料库产品等数据服务。
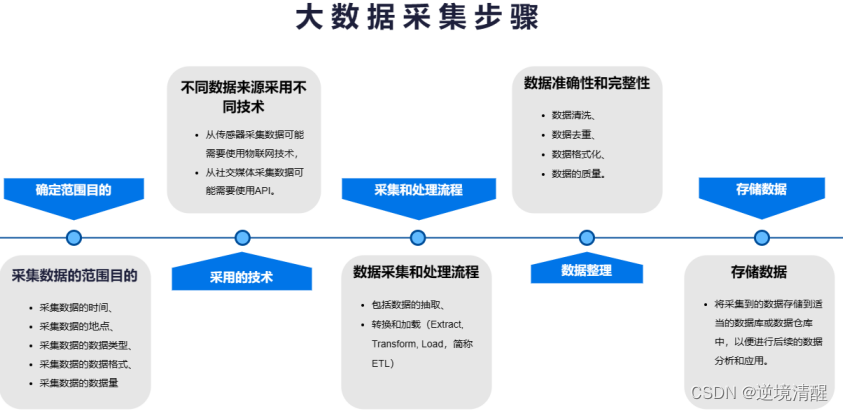
晨域软件公司在分布式环境下使用爬虫对网页的语料内容进行抓取下载,包含但不限于社交媒体语料、法律与政府文件语料、影视与对话记录语料、期刊论文语料。晨域经过网页的正则化、网页去重和网页去噪处理,将爬取的 URL 与内容进行一一对应并分类入语料库保存,为AI大模型训练提供稳定、可靠且合规的数据支持。
 :1299073570 网店:qushuiyin.taobao.com
:1299073570 网店:qushuiyin.taobao.com 


